

[改进的内存寻址机制]
Prescott也对内存寻址机制作了改进。内存延迟对性能的影响大,CPU等待数据的时间越短,性能越好。这个改进可以缓解因为缓存没有处理器数据而引发延迟的问题。CPU寻址时,必须要进行虚拟地址和物理地址的转换,这个转换依靠的就是两者之间的影射。这个影射关系信息就存放在TLB(索引转换缓冲),这个TLB是通过最近的主要内存数据从哪里读取,以及这些数据的读取频率的经验,来存放影射关系。如果映射失败,CPU寻址就必须将所有的物理内存从头到尾搜索一遍,这将消耗大量的CPU周期。所以如果能提高TLB的映射信息存放准确率也就能提高CPU性能。所以Intel又对Prescott的TLB作了改进,将目前Northwood的TLB的64个入口,提高到了Prescott的TLB的128个,很明显,这样CPU寻址的准确性将进一步提高,可以缓解因为缓存没有处理器数据而引发延迟的问题,从而提高CPU性能。
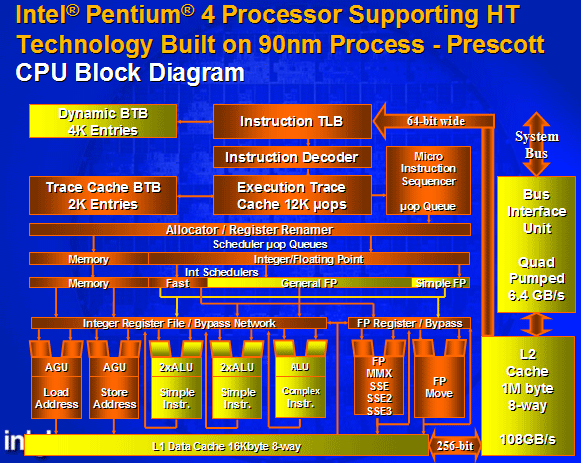
[最新版的双手互搏----改进的超线程]
Hyper-Threading 技术也是Intel的法宝之一,在理想的多任务环境下可以提高CPU的性能25%左右。这次Intel也没有放弃在Prescott身上继续改进这项技术。不过到目前为此Intel仍没有透露第二代超线程技术与前一代相比有那些改进之处,只是宣称第二代超线程技术可以更充分利用硬件资源,多任务下性能表现更为出色。此前支持超线程技术的Northwood内核每个线程可以处理63个微操作,两个线程只支持到126个微操作,而最新的Prescott内核则可以同时处理252个微操作。
再从预取机制上来看,Northwood内核中每个时钟周期只能预取3条指令,向流水线传送的指令数也是3个,但实际情况下,每条线程在每个时钟周期都会占据1.5~2条指令,因此在启用双线程时,如果每条线程需要占据2条指令时,3条指令就不够分配,会发生一条线程满载,一条线程吃不饱的情况,不能完全发挥超线程性能。而在Prescott中,预取指令数增加到4个,恰好可以同时满足两条线程满负荷时对指令的需求。
第三,为能让Prescott更好的对线程以及逻辑处理器进行任务调配,更好地给两个逻辑处理器分配L1缓存,Intel还加入了两个SSE3同步指令:MONITOR 和MWAIT。MONITOR会在内存中建立一个区域,然后CPU会监视其中的信号;而MWAIT则告诉CPU可以临时挂起处理器、线程或者逻辑处理器。对超线程程序有很大的帮助,但现在的问题是:要支持这两个新命令,软件必须被重新改写,加入对其的支持。所以对于现有程序来说,这些指令还是镜中花、水中月,没有什么实际意义。
[MMX的最新继承者--- 目前缺少支持的SSE3]
从MMX到SSE 再到SSE2,Intel开创了一个多媒体指令集的快速发展道路。所谓指令集就是对一些常用的指令集合用一套快速的计算方法以硬件集体管的形式直接设计在CPU内部,硬件集体管的直接运算,当然要比常规的多道指令运算要快的多。Prescott核心的另一重大改进是就是包含了新的SIMD指令集。起初它被称为PNI(Prescott新指令),正式发布Prescott时它自然也有了一个新的,更显耀的称呼—SSE3。Prescott核心中的SSE3分为五个应用层,共包括13条指令集包。

第一层“数据传输命令”,只有一条指令:FISTTP,它有利于x87的浮点转换成整数,并可以大大提高优化的效率。
第二层“数据处理命令”,共五条,分别是ADDSUBPS,ADDSUBPD,MOVSHDUP,MOVSLDUP,MOVDDUP。增强了复数的运算,主要用来简化复杂数据的处理过程,适应未来数据处理流量将会越来越大的情况。
第三层“特殊处理命令”,只有一条:LDDQU。用于视频解码,用来提高处理器对处理媒体数据结果的精确性。
第四层 “优化命令”,共四条指令,分别是HADDPS,HSUBPS,HADDPD,HSUBPD,针对单指令多数据流进行优化,主要偏重于处理3D图形,这对游戏爱好者是一个福音。
第五层“超线程性能增强”,有两条针对线程处理的指令:MONITOR, MWAIT,我们在前文已经解释过了。
比照SEE2的效能,我们可以乐观的估计,SSE3对CPU性能,尤其是在专门针对SSE3优化的软件和图像插件中会有一个明显的提升。这一点也肯定会在将来的测试软件中表现出来。但眼前的问题是,有马没有鞍,尽管Intel在去年夏天就为软件开发者公布了SSE3指令指南,但目前基本还没有软件支持这些新指令,对用户来说这些SSE3指令还都是空中楼阁看得见,摸不着。不过这一点倒没有被苛刻媒体或用户批评,因为大家都明白以Intel的影响力,出现大量支持SSE3的软件是早晚的事,我们倒不必为此担心,此外C++ 8.0编译器已经支持SSE3,开发工具支持SSE3更意味着SSE3软件将大量涌现。











