

[通通透透看TurboCache——原理及技术分析]
TurboCache的中文名为“智能加速引擎”,其最大的一个特性就是支持了将图像直接渲染到内存。顾名思义,直接渲染到内存的技术便是通过PCIE的总线通道,直接对系统内存进行读写访问,而读写的内容便是以往需要用显存来存放和处理的图象数据。
在AGP平台中,板载显卡其实使用了与此类似的技术,但那时的图形核心只能通过AGP总线对内存进行访问,并且我们需要在Bios中划分出固定容量的内存,来放置图形处理需要的顶点和纹理数据。这样做有两点不足:首先AGP总线的带宽不能满足越来越高的数据传输需要,大大限制了核心性能的发挥;其次在内存被固定的划分给图形核心后便不能改变容量,而系统也不能对这部分内存加以利用,这便造成了内存资源的浪费。
TurboCache技术很好的解决了这两个问题。由于PCIE总线的传输带宽远高于AGP总线,因此图形核心能够高速的与内存进行数据交换。如此一来显示核心便能够直接的利用内存,当进行纹理渲染时能够实时的对内存进行读取和写入操作。除此之外,对内存的实时调用也另TurboCache技术不需要划分固定容量的内存,系统能够根据图形处理工作的需要来访问内存。
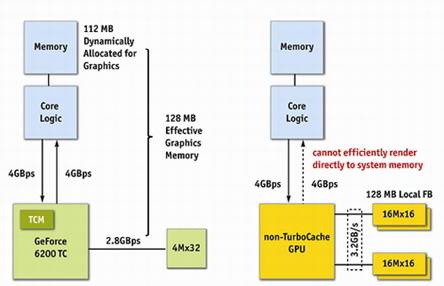
再来看看与同样采用PCIE总线,但没有使用TurboCache技术产品的对比。我们以16MB/32bit显存版本的GeForce6200TurboCache为例,可以看出,由于利用了nForce4平台的双向PCIE总线带宽以及显存的带宽,GeForce6200 TurboCache显示核心能够与系统内存进行上下行各4GB的数据交换,并且还能与本地显存通过2.8GB/s的带宽交换数据。
而普通的128MB/64bit的PCIE显卡,虽然连接到双向8GB/s的PCIE总线,但由于只利用板载显存因此只能使用单向的下行4GB/s的带宽用于核心与显存的数据交换,而本地显存带宽即使为3.2GB/s,但图形核心的整体效率也大打折扣。
此外,从这张图中我们也能够清楚的了解到,采用TurboCache技术的这款产品只需要板载16MB的显存,但通过动态分配最高达112MB的系统内存,实现了128MB的显示存储系统。而没有采用TurboCache的产品如果想要拥有128MB的显存容量,就只能通过显卡板载的方式来实现了。二者相比,规格和成本已经见了分晓。











