

[ATi X1900系列简介一:核心篇]
在之前驱动之家的评测文章中,我们评测室已经为大家介绍过了ATi X1900系列显卡。在这里我们再次为大家进行一下简单的介绍,更加详细的介绍请大家到[url=http://hardware.mydrivers.com/pages/200601242120_62497.htm]“48管线”的期待——X1900XTX详细测试[/url]中去了解。
跟R520一样,R580也使用了90nm制造工艺,48个像素着色处理器,8个顶点着色处理器,256-bit 8通道GDDR3显存,支持PCI Express x16,动态工作电压和工作频率控制,双DVI输出支持,但是,R580的晶体管数目达到了骇人听闻的3.84亿个,这些多出来的晶体管,大部分都被用到了新的像素渲染处理单元中去了。要满足这样一个“庞然大物”(其实体积并不算太大,但是能量消耗却实在是……),ATi要求最少450W的电源,要有30A的12V输出,如果是组成X1900 CrossFire则要求使用550W电源,12V要提供38A的输出能力才可以。看来现阶段玩家们所使用的电源在满足X1900 CrossFire上还不太容易做到。
R580和R520师出同门,都是X1000系列GPU,所以,它继承了R520的全部能力,包括Ultra-Threaded Shader Architecure(超线程渲染结构)、Shader Model 3.0、改良的显存控制器Ring Bus Memory Controller、用于屏蔽不可见渲染的Hyper-Z、HDR+AA(高动态渲染加上全屏抗锯齿,这是ATi引以为傲的技术)、128位的浮点指令渲染、自适应的抗锯齿、AVIVO、内建两个Dual Link DVI输出等等
48个像素渲染处理器。我们知道R520有16个像素渲染处理器,7800GTX有24个,而X1900一下子比X1800增加了两倍,达到了史无前例的48个,这是为什么呢?
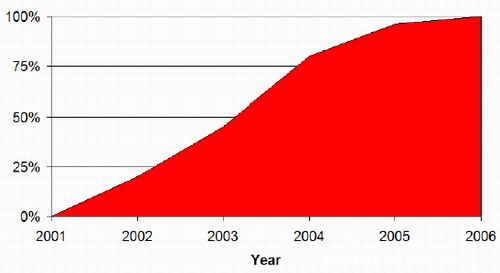
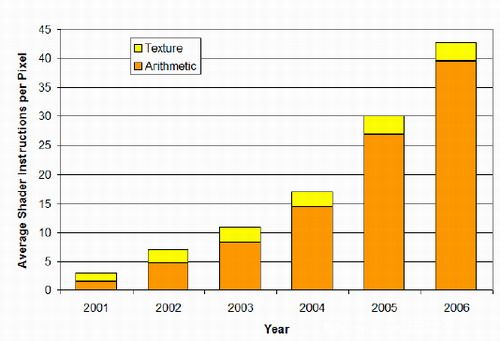
ATi的研究工作表明,自从微软2001年在DX8中导入可编程的渲染引擎后,渲染处理在游戏中变得非常普遍,而渲染指令的复杂度也在以每年1.8倍的速度增长。渲染指令大致可以分为两类:纹理操作和算术处理操作,随着游戏的进步,算术处理操作的比重正在不断加大,最近的游戏研究表明算术操作:纹理操作=5:1,下一代游戏的比重还在加大。算术操作和纹理操作最大的不同在于,纹理操作依赖于显存容量和带宽等外部因素,当外部条件不足时增加纹理处理单元对性能没有帮助,而算术操作能力不取决于外部因素,是由GPU内集成的算术操作单元的能力和数量决定的。这两者之间相互还有关系,通过像素渲染程序可以生成纹理,通过渲染调整还可以减少纹理模板的数量,这两种办法都可以用来降低存储纹理所必需的显存和带宽。
在微软提出的SM3.0规范中,最重要的新特性就是像素渲染的动态分支控制。在早期的SM中所有的指令和纹理拾取都要在每个像素上面施加一次,不管他们是否需要,而流控制则可以根据实际情况在需要的像素上执行渲染。ATi的设计正确理解了流控制的愿意,认为动态流控制提倡的是让不同数据块执行不同的操作,为实现此目的,X1000系列引进了新的超线程技术,它通过一个庞大的联合线程计数器、小线程单元、专门的分支执行单元和一个巨大的、高性能的任务堆栈列表,在高速动态流控制和扩展并行处理之间取得最佳平衡。











