

在游戏领域,基于RDNA 2架构的Radeon RX 6000系列显卡已经开始闪亮登场。在高性能计算领域,基于CDNA全新架构的新一代计算卡Instinct MI100也终于登台了!
AMD Radeon Instinct系列计算卡已经发展了多款型号,但是在此之前,AMD GPU一直都是一套架构打天下,游戏、计算不分家,自然不利于不同方向的深度优化。

今年3月份,AMD宣布了首个专门针对数据中心高性能计算而设计的CDNA架构,从此与RDNA游戏架构分道扬镳。二者虽然还有一些共通点,但在设计、优化上已经泾渭分明,在各自领域的性能、能效也更高。
而在产品命名方面,AMD计算卡也放弃了Radeon字样,不再称呼Radeon Instinct,而是简单地叫做Instinct。
AMD Instinct可以说是专为HPC高性能计算而生的,志在推动超级计算机进入百亿亿次计算时代(ExaScale)。
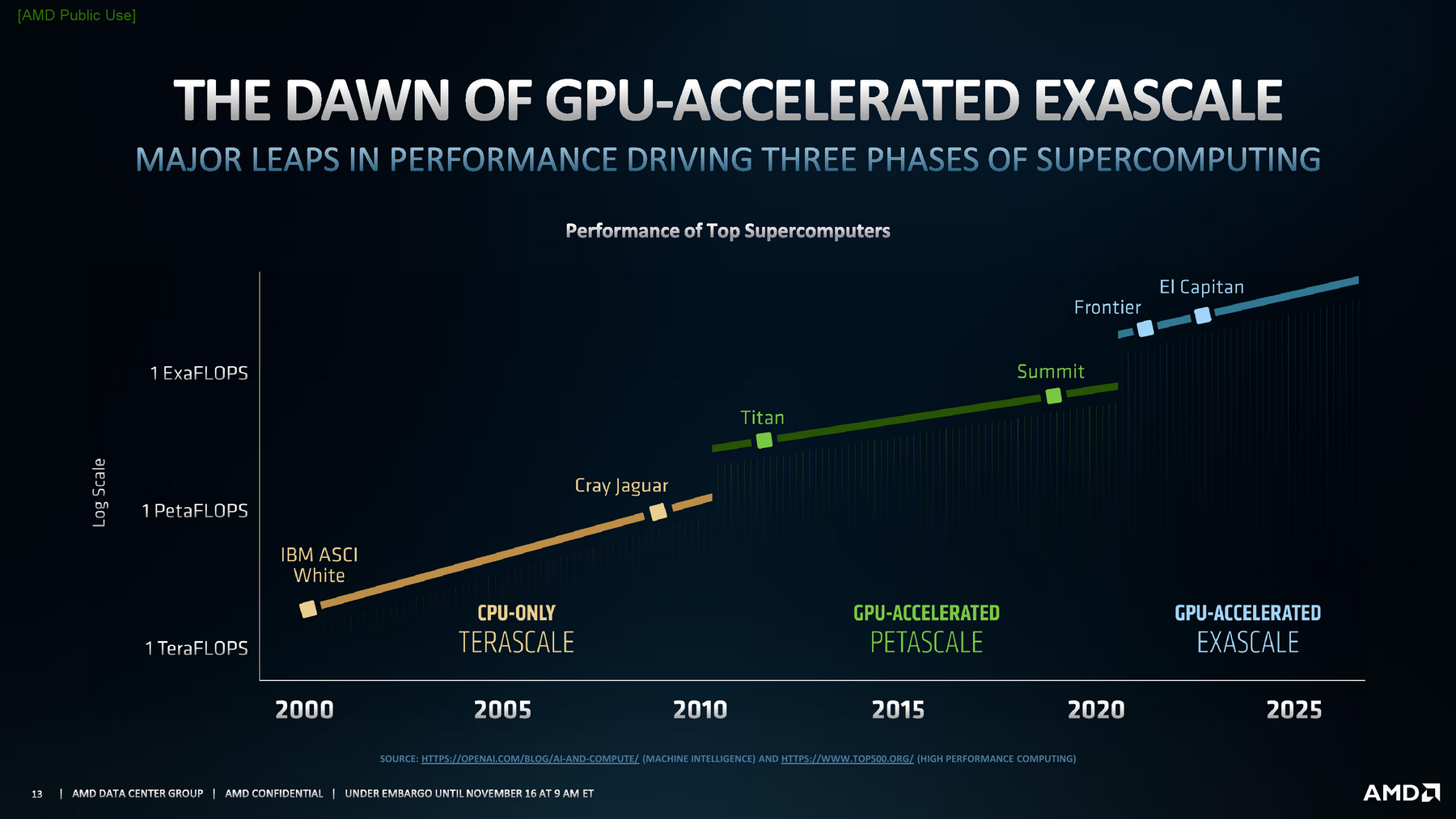

回顾历史,21世纪的前10个年头属于万亿次计算时代(TeraScale),完全依赖CPU运算;最近10个年头属于千万亿次计算时代(PetaScale),GPU加速运算展露锋芒。
不过近两年,传统的GPU加速计算也已经初显疲态,性能增强曲线也缓了下来,必须实现全新的突破。


CDNA架构和MI100加速卡就是这样的突破性产品,也是AMD开拓新未来的新旗舰。
AMD Instinct MI100是其迄今为止性能最高的HPC GPU,FP64双精度浮点性能首次突破10TFlops(也就是每秒1亿亿次),并在架构设计上专门加入了Matrix Core(矩阵核心),用于加速HPC、AI运算,号称在混合精度和FP16半精度的AI负载上,性能提升接近7倍。
另外,新卡的外观设计也令人眼前一亮,更有质感的拉丝外壳,深灰色调,非常沉稳大气。

它集成多达120个计算单元、7680个流处理器,搭配32GB HBM2,带宽高达1.23TB/s,同时支持PCIe 4.0,集成Infinity Fabric x16高速互联通道,峰值带宽达276GB/s(相当于PCIe 4.0 x16的大约4倍),而整卡功耗控制在300W。
计算性能方面,FMA64/FP64双精度为11.5TFlops(每秒1.15亿亿次),FMA32/FP32单精度为23.1TFlops(每秒2.31亿亿次),FP32 Matrix单精度矩阵计算为46.1TFlops(每秒4.61亿亿次),FP16 Matrix半精度矩阵计算为184.6TFlops(每秒18.46亿亿次),Bfloat16浮点为92.3TFlops(每秒9.23亿亿次)。

这些数字是什么概念呢?
就拿11.5TFlops的双精度性能来说,2000年排名世界第一的超级计算机ASCI White,这个指标也不过12.3TFlops,但却是付出了600万瓦的功耗、106吨的身材才获得的,Instinct MI100却只要300瓦、1.16千克。
换言之,如今的一块卡,就相当于20年前的一个大规模计算集群!

AMD上代计算卡Instinct MI50采用的还是Vega 20核心,60个计算单元,3840个流处理器,32GB HBM2显存带宽1TB/s,Infinity Fabric总线带宽92GB/s,功耗300W。
Instinct MI100的核心规模翻了一番,显存带宽提升了超过20%,Infinity Fabric带宽提升了整整2倍,但是功耗却完全没变(工艺应当也还是7nm),新架构的能效可见一斑。
新卡的性能更是不可同日而语,FP64双精度、FP32单精度性能均提升74%,FP32矩阵性能提升接近2.5倍,AI负载性能更是几乎7倍的飞跃。

在美国能源部旗下的橡树岭国家实验室,AMD MI100计算卡已经在支撑多项百亿亿次科研项目,涉及NAMD分子动力学模拟、CHOLLA星系形成研究、PIConGPU激光放射癌症疗法、GESTS流体动力学等等诸多前沿科技。

AMD Instinct MI100计算卡还有一个绝佳搭档,那就是AMD自家的霄龙数据中心处理器,慧与、戴尔、超威、技嘉等多家行业巨头都有提供这种双A方案。

当然了,只有硬件,是做不成高性能计算的,AMD同时一直在推进一站式软件解决方案ROCm。
从2016年初入江湖的1.x版本,2018年奠定基础的2.0版本,到2019年专注于机器学习的3.0版本,再到如今最新的4.0版本,AMD ROCm已经打造成了一整套针对机器学习、高性能计算的百亿亿次级开发方案,规划中的各项功能特性也基本都已经实现。

软件优化的力量无疑是巨大的,可以充分释放硬件潜力,比如说上代MI50,搭配ROCm 3.0的话性能相比于搭配ROCm 2.0可以提升3-4倍,而最新的MI100、ROCm 4.0联合,更是可以轻松带来5-8倍的性能提升。

AMD ROCm生态的进步速度非常快,已经有众多领域的头部厂商采纳和支持,而且它沿袭了AMD一贯的原则,那就是完全开源开放,非常方便代码迁移,比如说HACC(宇宙学)只用了一个下午,SPECFEM3D(地震学)半天就搞定,CHOLLA(天体物理学)花了几天,QUDA(量子物理学)也不过21天。











